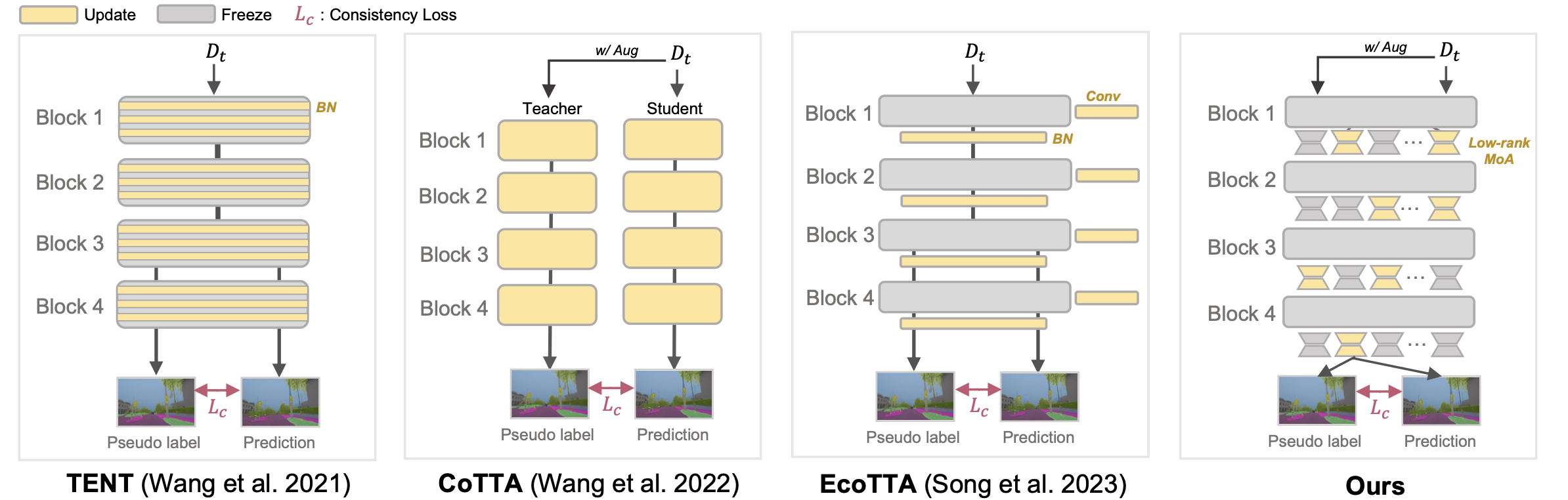
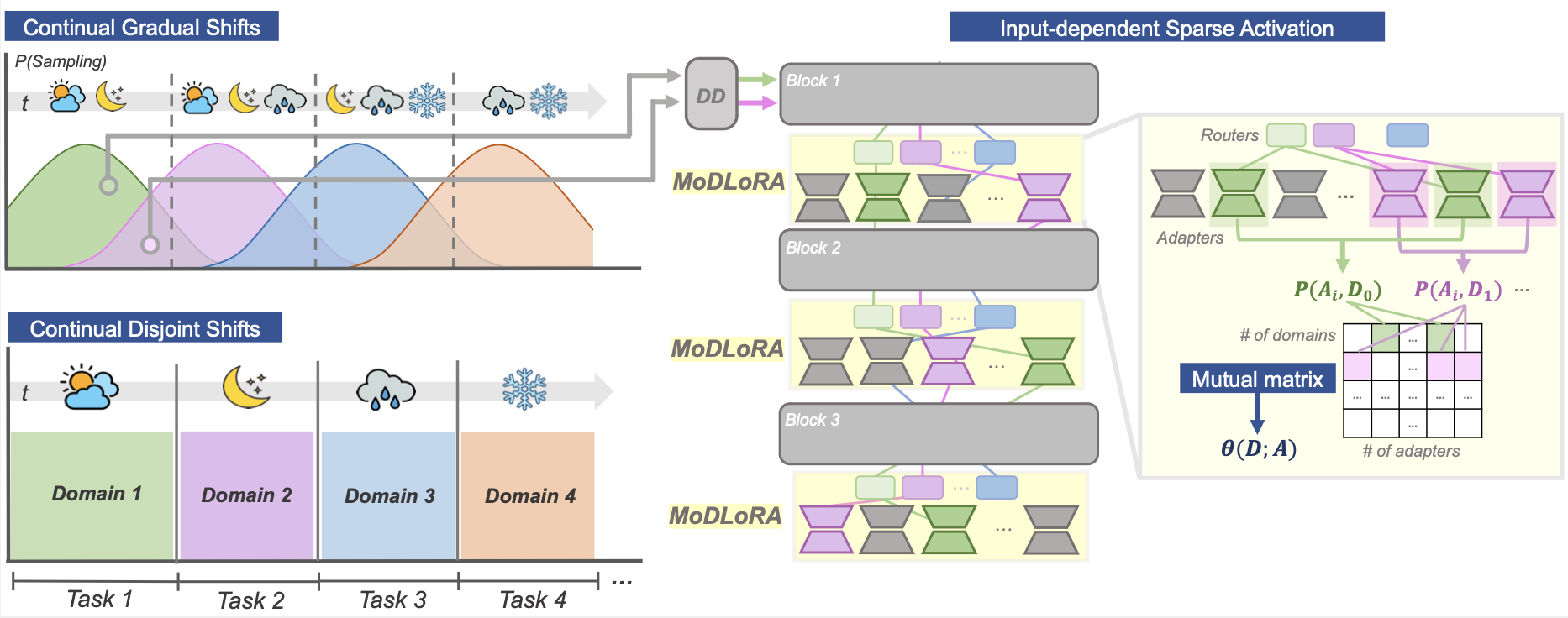
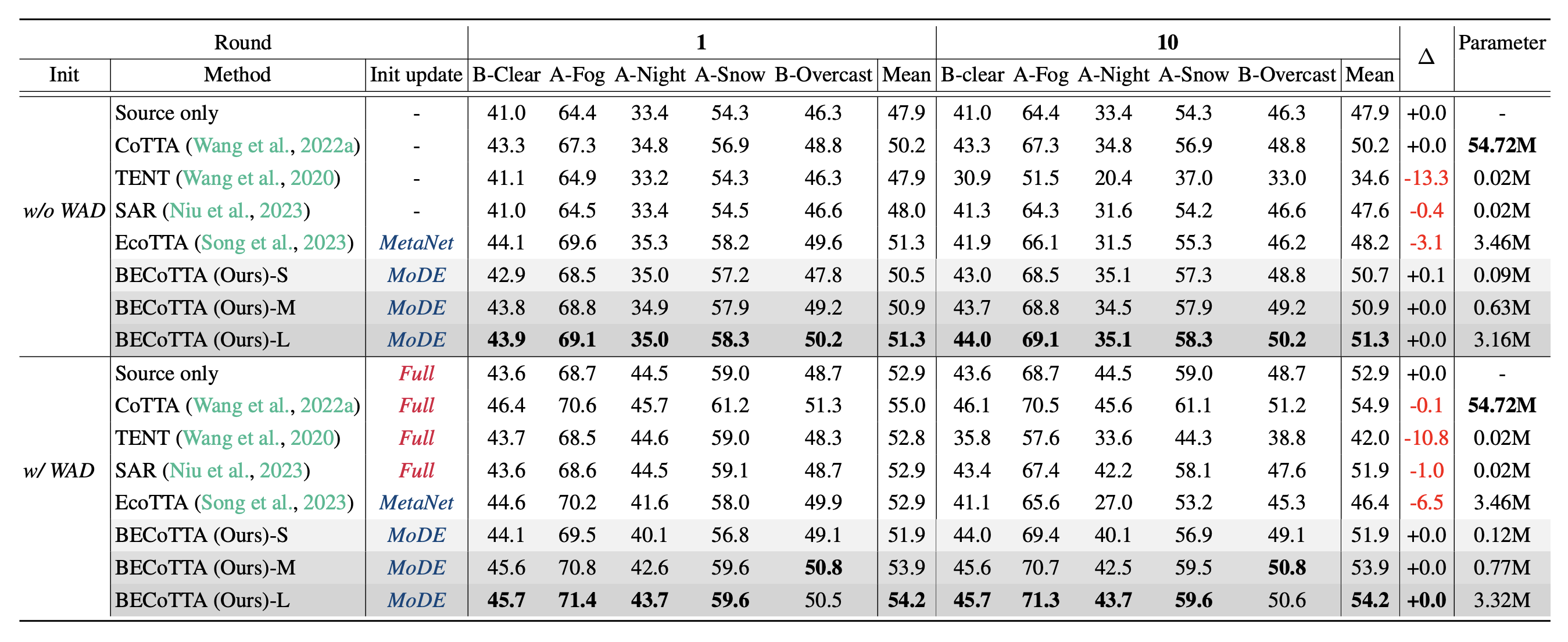
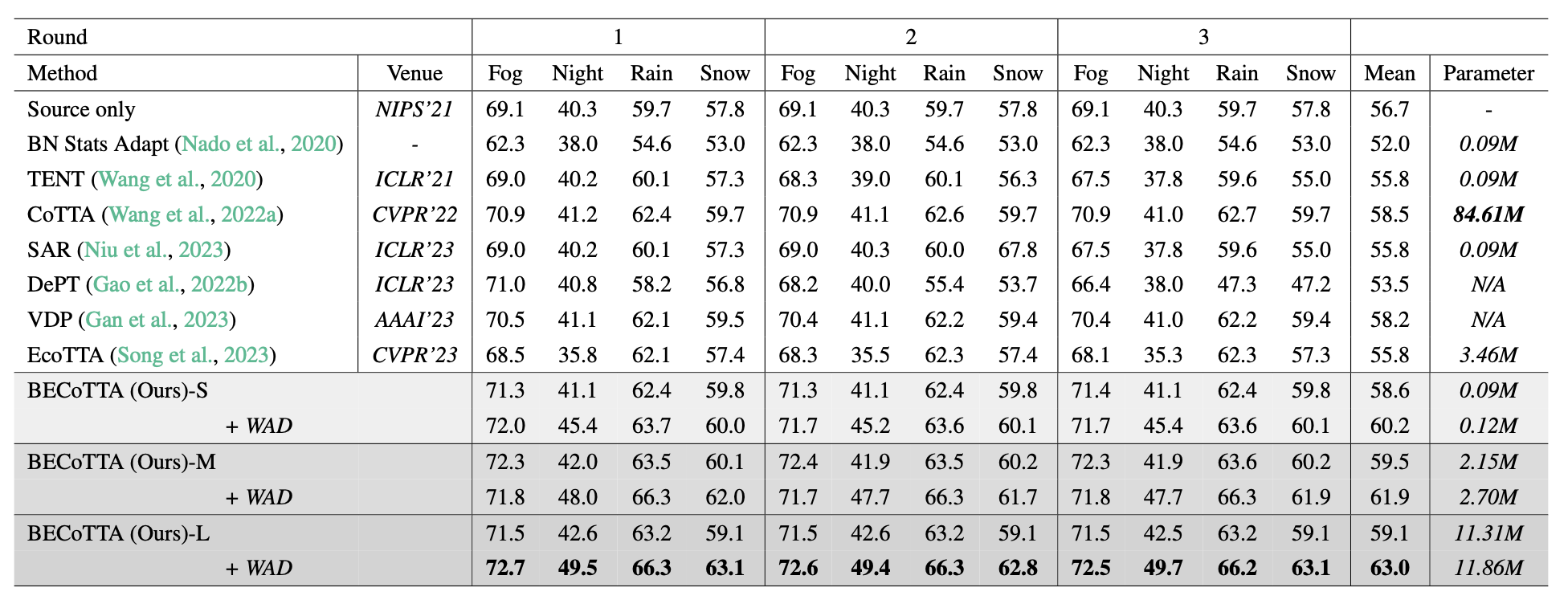
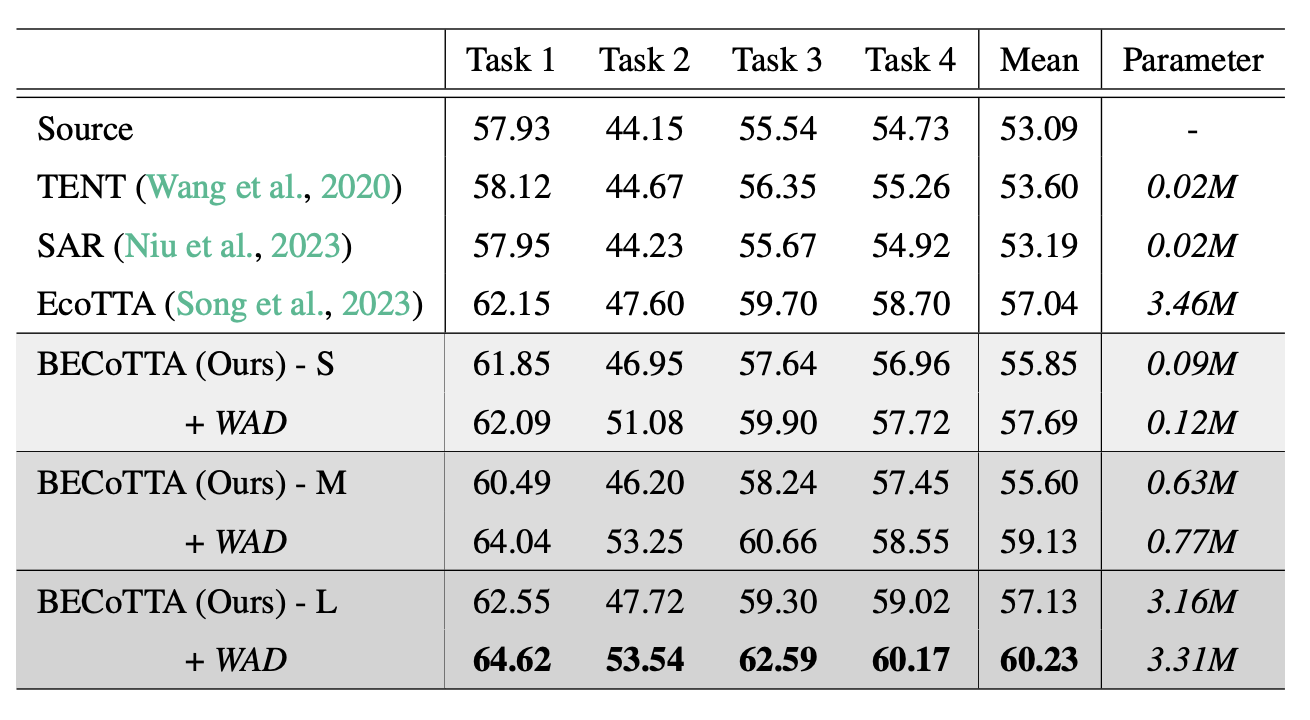
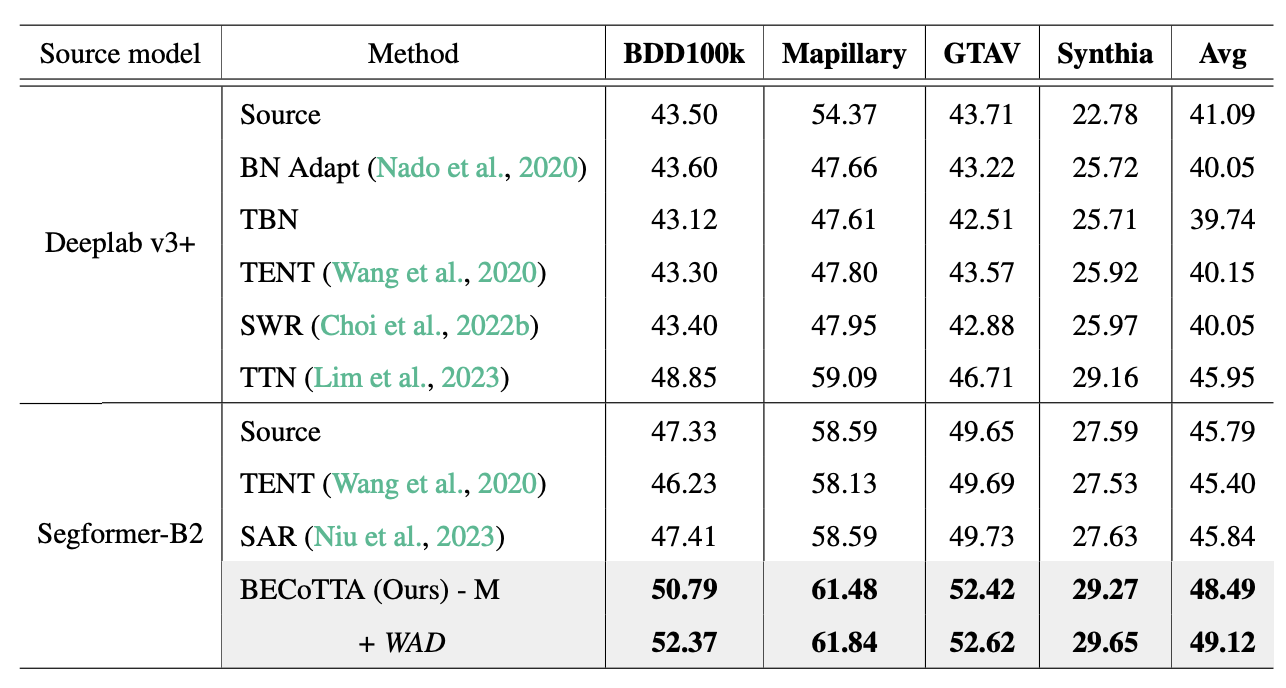
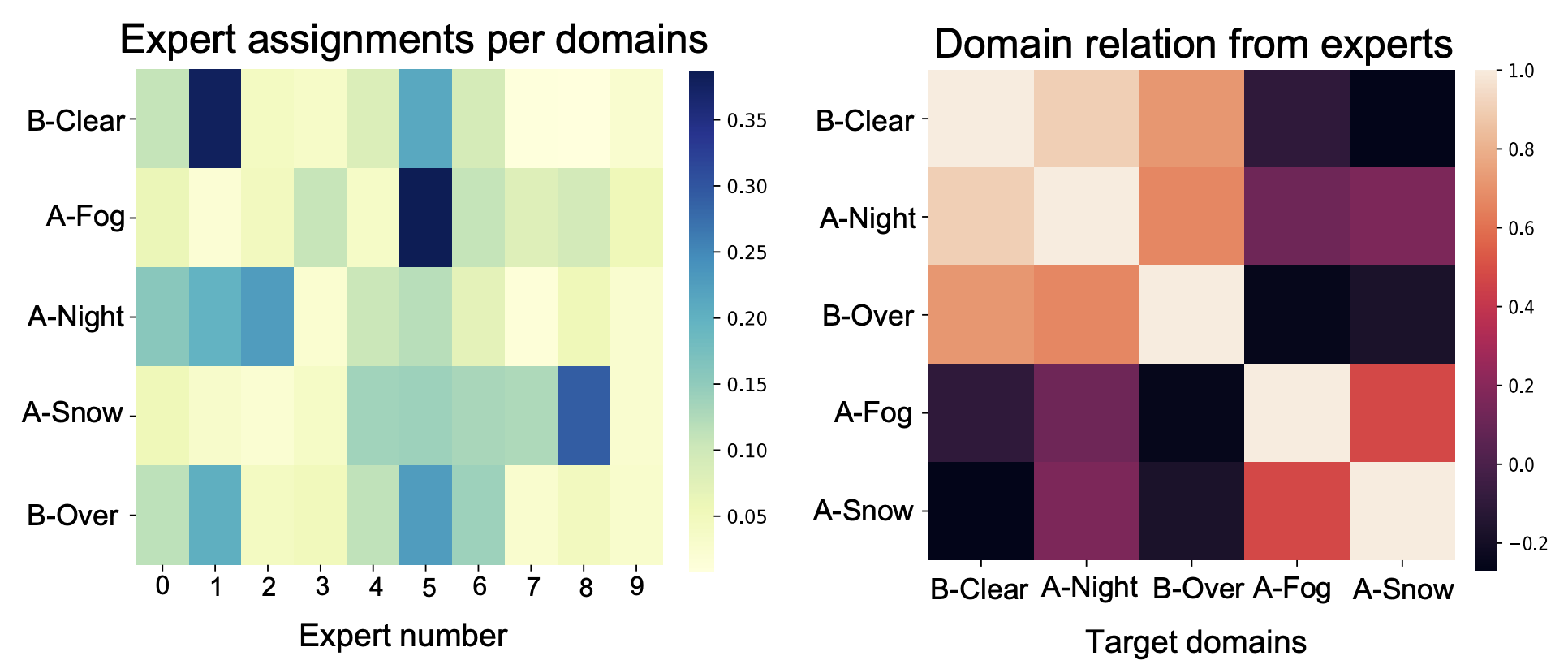
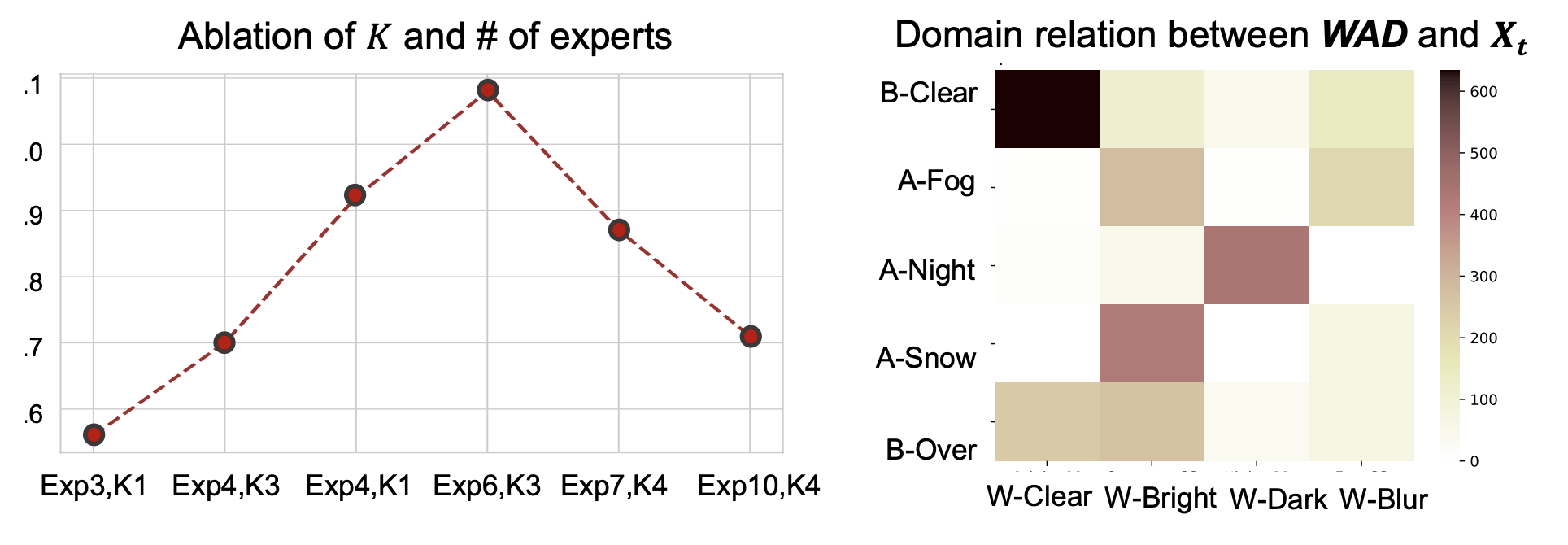
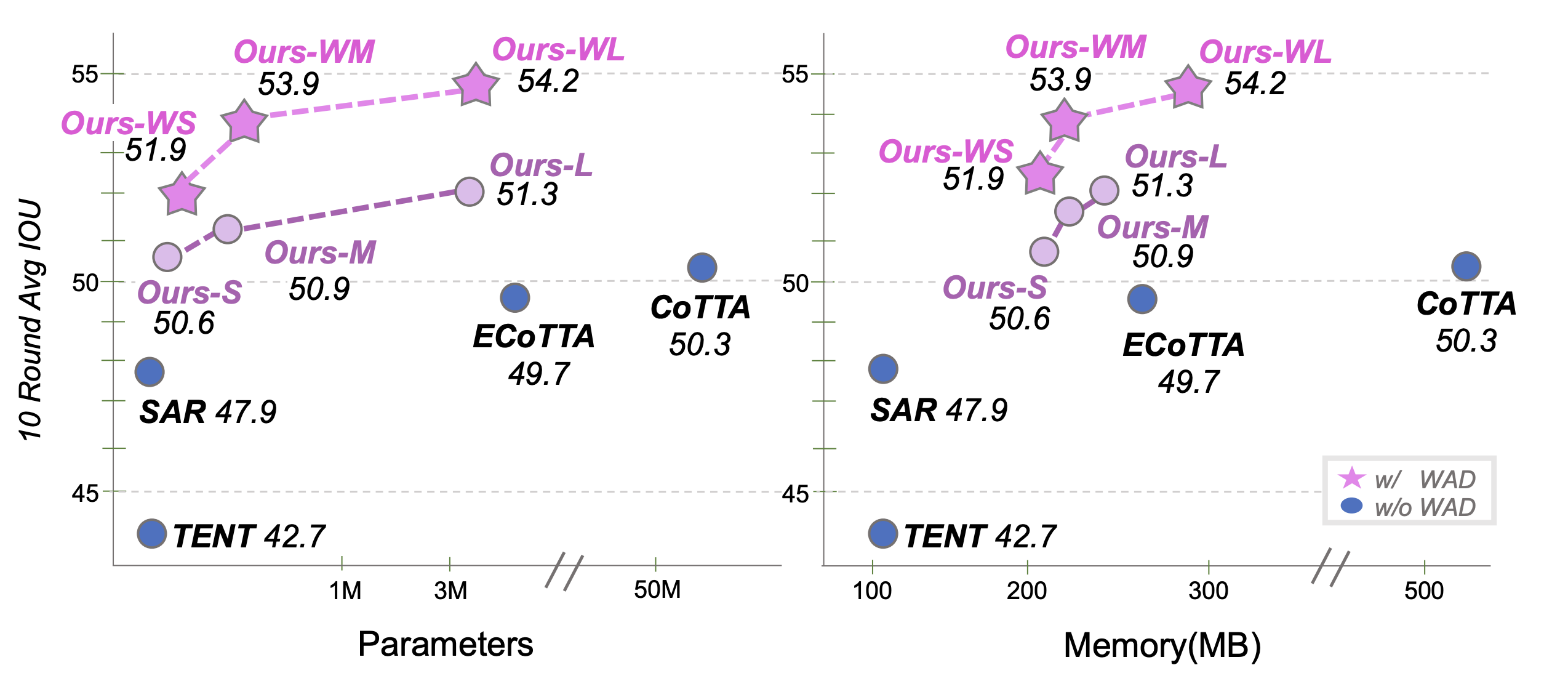
Continual Test Time Adaptation (CTTA) is required to adapt efficiently to continuous unseen domains while retaining previously learned knowledge. However, despite the progress of CTTA, forgetting-adaptation trade-offs and efficiency are still unexplored. Moreover, current CTTA scenarios assume only the disjoint situation, even though real-world domains are seamlessly changed. To tackle these challenges, this paper proposes BECoTTA, an input-dependent yet efficient framework for CTTA. We propose Mixture-of-Domain Low-rank Experts (MoDE) that contains two core components: (i) Domain- Adaptive Routing, which aids in selectively capturing the domain-adaptive knowledge with multiple domain routers, and (ii) Domain-Expert Synergy Loss to maximize the dependency between each domain and expert. We validate our method outperforms multiple CTTA scenarios including disjoint and gradual domain shits, while only requiring ∼98% fewer trainable parameters. We also provide analyses of our method, including the construction of experts, the effect of domain-adaptive experts, and visualizations.